
Un petit point d’attention avant de commencer : je débute dans le domaine des digital forensics. Le sujet m’amuse beaucoup, donc je profite de cet enthousiasme pour écrire mes aventures et les partager avec vous. Je préfère revenir ensuite sur mes billets pour les corriger plutôt que d’approfondir le sujet et risquer de perdre l’élan initial. Cet enthousiasme du débutant, c’est peut-être un petit effet Dunning-Kruger, mais il m’encourage.
Un peu de contexte
Il y a quelques semaines, Felix Burger, un de mes collègues de la TIB a évoqué cinq disquettes ZIP qu’il avait récupérées de Kamel Louafi, un architecte algéro-allemand. Ces disquettes étaient susceptibles de contenir des données liées au réaménagement du parc Welfengarten, où se trouve la Leibniz University Hanover.
Qu’est-ce qu’une disquette ZIP ?
Peut-être n’en avez-vous jamais vu, mais de 1995 à 2003, l’entreprise Iomega a vendu ces super-disquettes, dont la capacité était de 100, puis 250, puis enfin 750 Mo, alors que la disquette standard embarquait 1,44 Mo. Ces disquettes sont également plus épaisses.

RetroEditor, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
Par ailleurs, contrairement aux disquettes 3 pouces ½, elles ne disposaient pas de mécanisme de protection, ces interrupteurs mécaniques permettant d’interdire l’écriture.
Évidemment, elles nécessitent un lecteur spécifique. Il ne restait plus qu’à trouver un lecteur ZIP. Sur ebay, de nombreux lecteurs sont disponibles à moins de 100 €, mais leurs caractéristiques et leur degré d’usure sont difficiles à évaluer. Un des collègues disposait d’un lecteur ZIP externe, mais celui-ci fonctionnait avec un port parallèle, et nos ordinateurs professionnels n’en disposaient pas. Or il se trouvait que j’avais récupéré quelque temps auparavant un lecteur récent, qui utilise l’USB à la fois pour le transfert de données et pour l’alimentation, très pratique donc.

A l’occasion de la réunion annuelle de l’équipe à Hanovre, j’ai donc amené cette charmante machine.
Connecter le lecteur
J’ai commencé mes petites expérimentations dans le train me menant à Hanovre. Je voulais tester la récupération de données à partir d’une disquette ZIP qui restait dans le lecteur et qui avait appartenu à un membre de ma famille. Mais je voulais faire les choses un peu sérieusement – j’ai donc tenté d’éviter, comme en conditions réelles, d’altérer le contenu de la disquette. Comme je le disais dans un précédent billet, il est très facile de modifier sans le vouloir le contenu d’un support amovible, aussi la plus grande précaution doit-elle être de mise.
Lorsque vous connectez un support plug-and-play, vous accédez au contenu du support sans avoir à intervenir, configurer ou installer un pilote. C’est pratique, mais par défaut l’accès est fait en read/write, ce qui va évidemment augmenter le risque de modifier le contenu du disque. Je voulais donc éviter ce comportement.
Désactiver le montage automatique
J’ai donc saisi la commande suivante (sous Ubuntu) :
systemctl stop udisks2.serviceCette commande désactive temporairement – jusqu’au redémarrage de l’ordinateur – l’auto-montage, c’est-à-dire la configuration automatique de l’accès à un système de fichiers.
Connecter le lecteur
Il est maintenant possible de connecter mon lecteur et de le monter comme je l’entends – en read-only, en l’occurrence. Une fois connecté (en USB, pour ce cas), je cherche son petit nom pour le monter. GNU/Linux considère tout objet manipulable comme un fichier, y compris les supports amovibles. Pour l’identifier, j’utilise la commande fdisk, qui avec son option --list liste tous les supports et partitions, montées ou non :
$ sudo fdisk --list
(...)
Disque /dev/sda : 239,03 MiB, 250640384 octets, 489532 secteurs
Disk model: ZIP 250
Unités : secteur de 1 × 512 = 512 octets
Taille de secteur (logique / physique) : 512 octets / 512 octets
taille d'E/S (minimale / optimale) : 512 octets / 512 octets
Type d'étiquette de disque : dos
Identifiant de disque : 0xd8e9a7f7
Périphérique Amorçage Début Fin Secteurs Taille Id Type
/dev/sda1 2048 489471 487424 238M c W95 FAT32 (LBA)A la fin d’une longue liste de supports, physiques ou virtuels, accessibles sur mon poste, j’ai donc mon périphérique, avec son petit nom (/dev/sda) et sa ou ses partition(s) – ici, il n’y en a qu’une, il s’agit de /dev/sda1.
Dans un système GNU/Linux, tous les équipements sont listés dans le dossier /dev (pour devices), ainsi que les partitions qui ont été créées sur chacun d’eux.
Monter en read-only
On va maintenant monter la partition du support en question (oui, parce qu’on ne monte pas un support mais une « partition », c’est-à-dire la division d’un espace de stockage en unités distinctes, disposant de leur propre système de fichiers). Ici, une seule partition existe, ce qui nous facilite la tâche. Monter la (les) partition(s) d’un support n’est pas obligatoire pour créer une image disque mais permet d’explorer le contenu afin de décider de la suite de la procédure.
Voici la ligne de commande que j’ai utilisée :
sudo mkdir /media/zip_disk && sudo mount --options ro /dev/sda1 $_
Je crée un dossier vide dans /media puis y monte ma partition en read-only (--options ro). (Notez le raccourci $_ pour remplacer le dernier argument de la commande précédente, à savoir /media/zip_disk.)
J’ai désormais accès, à mon point de montage /media/zip_disk, au contenu logique de l’image disque, c’est-à-dire les dossiers et fichiers tels qu’ils sont consultables sur la disquette ZIP.
Utiliser un bloqueur d’écriture
Cette solution est déjà assez satisfaisante, mais pourrait n’être pas suffisante dans certains cas particuliers. En effet, même avec un montage en lecture seule, il peut arriver que la commande mount écrive sur le disque ; voici ce que dit le manuel de la commande à ce propos :
Note that, depending on the filesystem type, state and kernel behavior, the system may still write to the device. For example, ext3 and ext4 will replay the journal if the filesystem is dirty.
Dans le cas où la preuve de l’intégrité du processus de collecte doit être faite, et en particulier si les données doivent être utilisées dans un contexte légal, il est donc indispensable de prendre des précautions supplémentaires1, et d’utiliser un bloqueur d’écriture. Je laisse le soin de décrire ce processus à nos collègues du AIDA Capture Lab, dans leur fiche sur les disquettes et lecteur ZIP.
Créer une image disque
Pourquoi créer une image disque ? En résumé, cela permet de reproduire le plus exactement possible le contenu binaire d’un support et ainsi de le « dématérialiser », ou du moins de le copier sur un autre support. Le processus est absolument fondamental dans le domaine des digital forensics, où la preuve de la non-altération est critique, mais il peut être également nécessaire en préservation numérique patrimoniale2.
Expérience personnelle : j’ai fait une première image avec les précautions mentionnées plus haut (montage en read-only) puis ai exploré le contenu du disque sans trop de précaution – mais sans intention de le modifier. J’ai ensuite réalisé une seconde image, qui s’est révélée d’un mégaoctet plus petite que la précédente ! Je ne m’explique pas cette différence, mais elle est substantielle.
Pour la réalisation d’une image disque sous GNU/Linux, je vous renvoie à nouveau aux consignes du AIDA Capture Lab qui recommande l’outil Guymager. Guymager est un outil de création d’images disques qui ne fonctionne que sous GNU/Linux mais a l’avantage de disposer d’une interface graphique, pour les personnes qui ne sont pas à l’aise avec la ligne de commande.
Parmi les paramètres de Guymager, il y a le format de l’image disque. L’AIDA Capture Lab recommande le format brut .dd, qui est une réplique exacte, non compressée, d’un disque, produite par l’outil dd et ses dérivés. Mais il est également possible de choisir un format compressé comme Encase afin de gagner de l’espace – on peut s’attendre à ce que l’image disque contienne beaucoup d’espace vide, qui se compresse aisément. En outre, le format brut est une simple copie des octets du disque et ne contient pas de métadonnées, ce qui fait que les outils tels que Guymager produisent un autre fichier compagnon, avec l’extension .info pour stocker les informations liées au processus de création d’image.
Il est également possible d’utiliser un outil en ligne de commande assez commode pour créer une image disque. Peter Eisner, un de mes collègues de la TIB qui travaille sur le processus de création d’images disques, a suggéré dc3dd. Il s’agit d’un dérivé de l’utilitaire Unix dd, développé par le Department of Defense Cyber Crime Center. Il a l’avantage de créer une empreinte numérique de l’image et de générer un fichier de métadonnées la stockant, ainsi que d’autres informations sur le processus de création d’image. Voici la ligne de commande que Peter nous suggère :
dc3dd if=/dev/sda of=~/disk_images/mydisk.dd hash=md5 log=~/disk_images/mydisk.txtLe résultat de cette opération est un fichier mydisk.dd qui est une copie exacte du support, non compressée – donc l’image fait la taille exacte du disque, c’est-à-dire 250 mégaoctets / 239 mébioctets – et un fichier mydisk.txt qui comprend le log de l’opération de création d’image disque.
Monter l’image pour explorer le contenu
Comme une partition de support, l’image disque peut être montée afin d’être explorée. Avec certaines distributions GNU/Linux, il suffit de double-cliquer sur l’image pour la monter, mais ce n’était pas mon cas avec un Ubuntu « brut ». J’ai donc dû monter l’image avec la ligne de commande suivante :
sudo mkdir ~/zip_image && sudo mount --types vfat --options ro,loop,offset=1048576 mydisk.dd $_Cette ligne de commande demande un certain nombre de paramètres :
- Le système de fichiers ; ici il s’agit de vfat, une variante des systèmes de fichier FAT pour les volumes virtuels ;
- L’offset de début ; il s’agit du secteur de début multiplié par le nombre d’octets par secteur.
Ces informations s’obtiennent à l’aide de la commande fdisk -l déjà citée :
$ sudo fdisk --list mydisk.dd
Disque mydisk.dd : 239,03 MiB, 250640384 octets, 489532 secteurs
Unités : secteur de 1 × 512 = 512 octets
Taille de secteur (logique / physique) : 512 octets / 512 octets
taille d'E/S (minimale / optimale) : 512 octets / 512 octets
Type d'étiquette de disque : dos
Identifiant de disque : 0xd8e9a7f7
Périphérique Amorçage Début Fin Secteurs Taille Id Type
zip_250_image.dd1 2048 489471 487424 238M c W95 FAT32 (LBA)On peut désormais naviguer dans l’arborescence de l’image disque. Et y réaliser toutes les opérations d’exploration que l’on souhaite, sans risque d’altérer quoi que ce soit d’important.
Restaurer des fichiers supprimés
Vous le savez peut-être : lorsque vous supprimez un fichier sur votre ordinateur, et même si vous videz votre corbeille, l’ordinateur se contente de désindexer les données : il oublie leur adresse. Il ne réécrira à cet endroit que s’il a besoin d’espace pour ajouter d’autres données. Par conséquent, il est possible de restaurer des données supprimées tant qu’il n’a pas réécrit à cet endroit. Il y a certainement plusieurs moyens pour faire cela mais je vais vous en présenter un seul pour en faire la preuve.
L’outil
J’ai testé les outils TestDisk et PhotoRec, développés par Christophe Grenier, qui m’ont été signalés par mon collègue Peter Eisner. Ces outils sont faciles d’utilisation ; je ne démontrerai que PhotoRec car c’est celui qui a donné des résultats dans mon cas.
Une fois lancé l’outil avec la commande sudo photorec mydisk.dd, on obtient l’écran suivant :
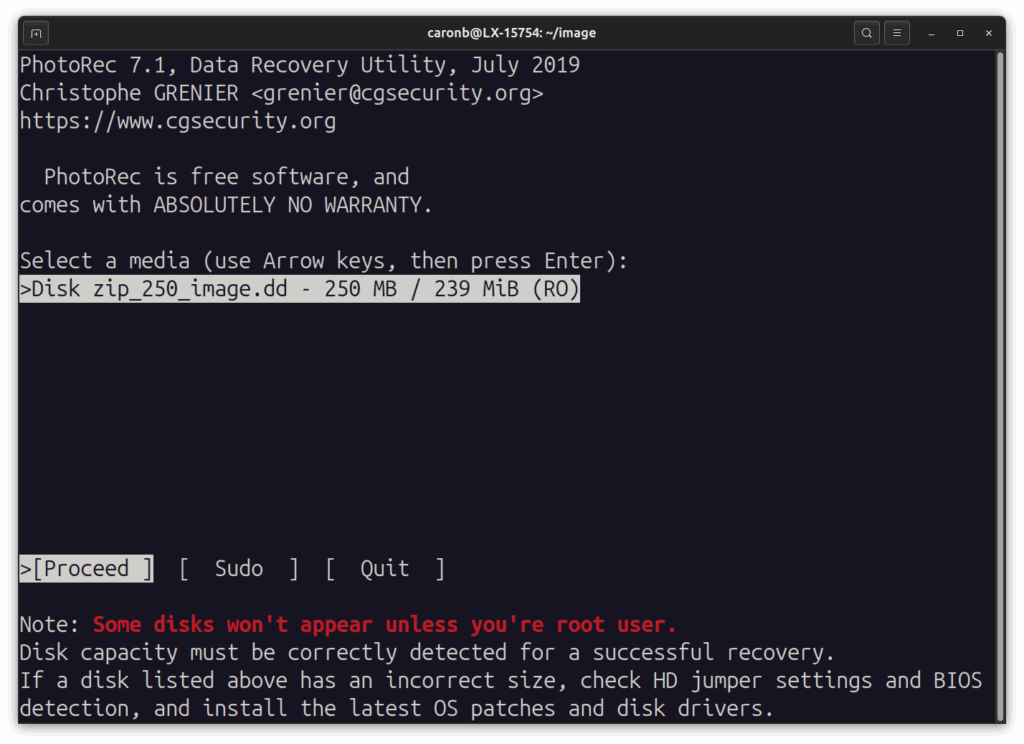
On sélectionne le support…
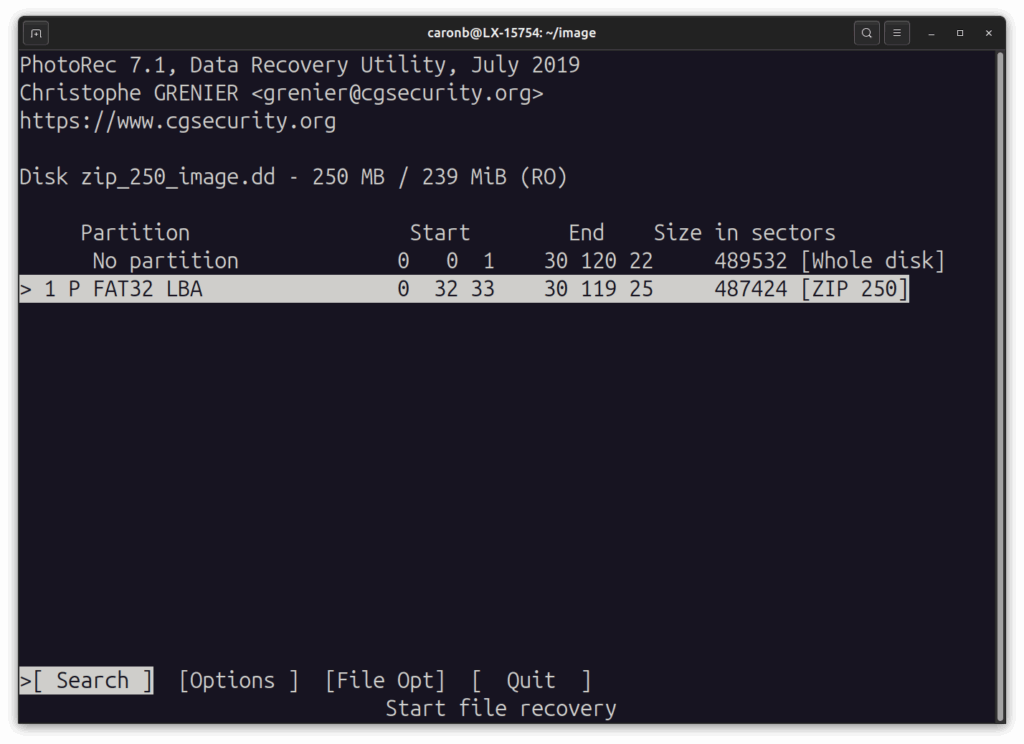
… puis la partition…
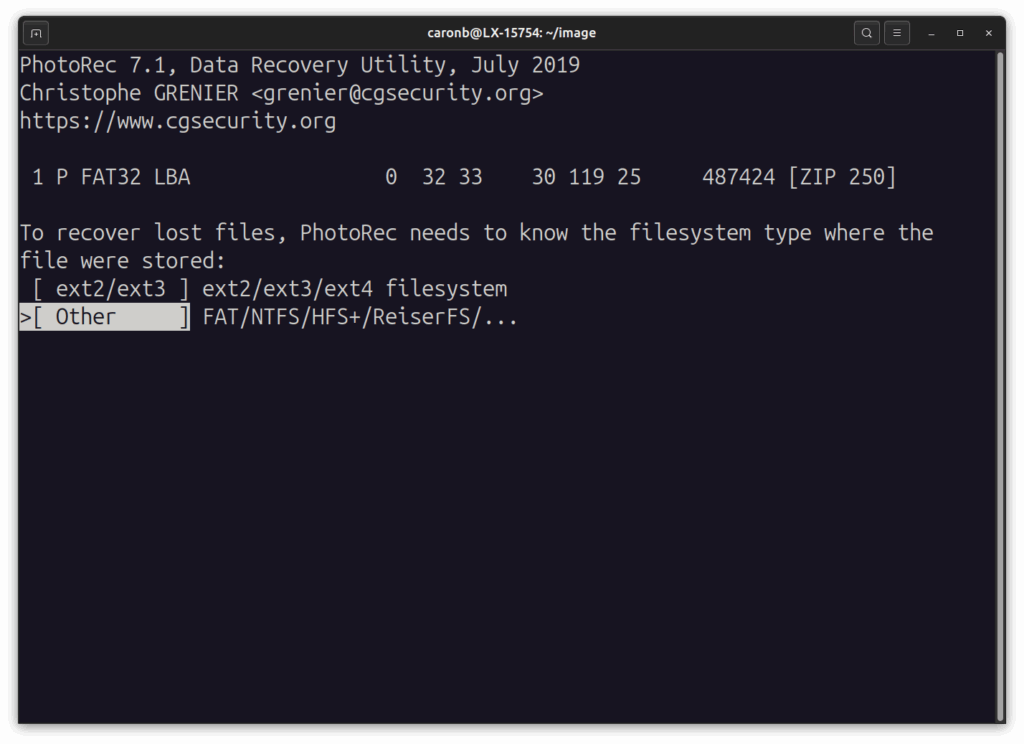
… puis le système de fichiers …
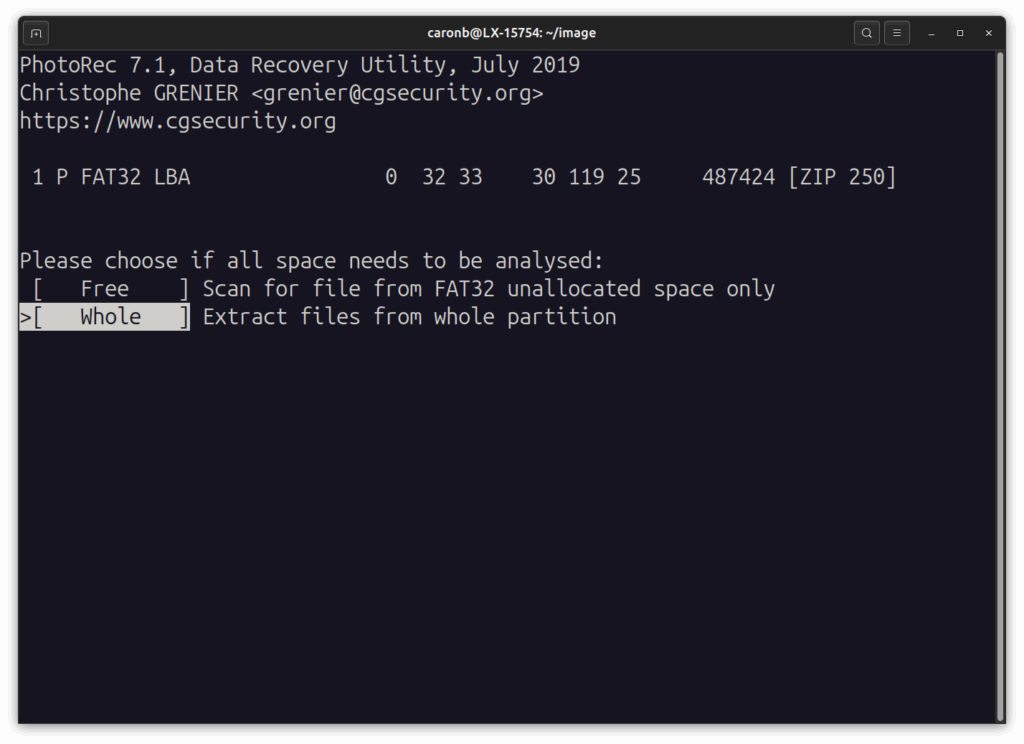
… on décide si on réalise l’analyse sur toute la partition ou seulement sur l’espace laissé libre…
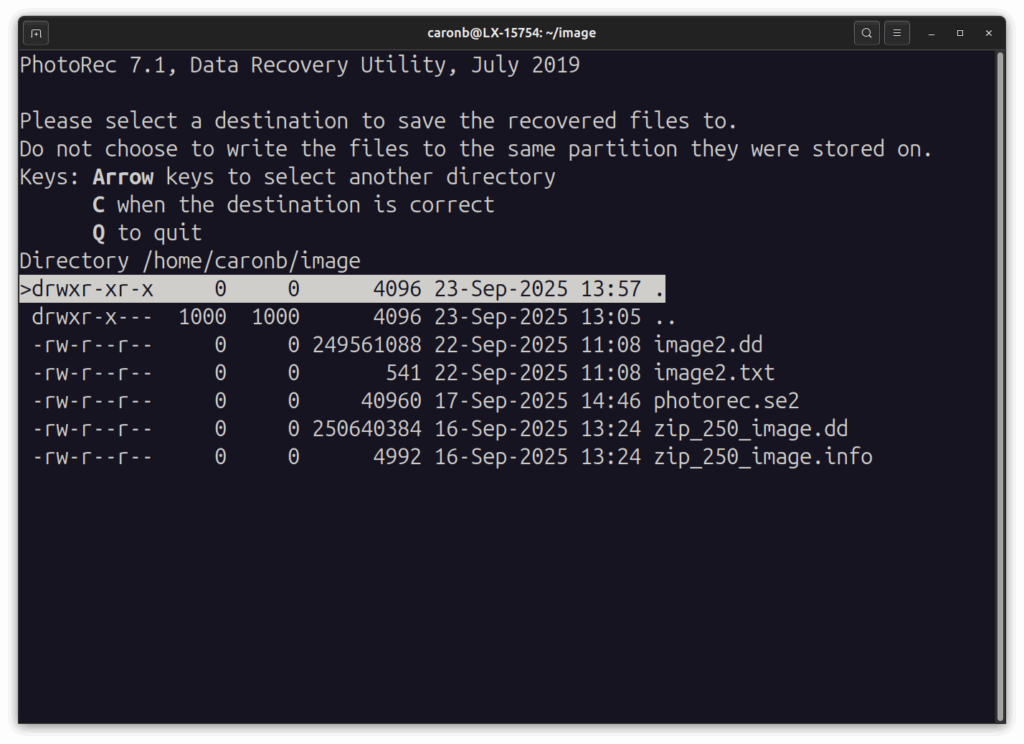
… on sélectionne le dossier où les fichiers doivent être extraits et on appuie sur C …
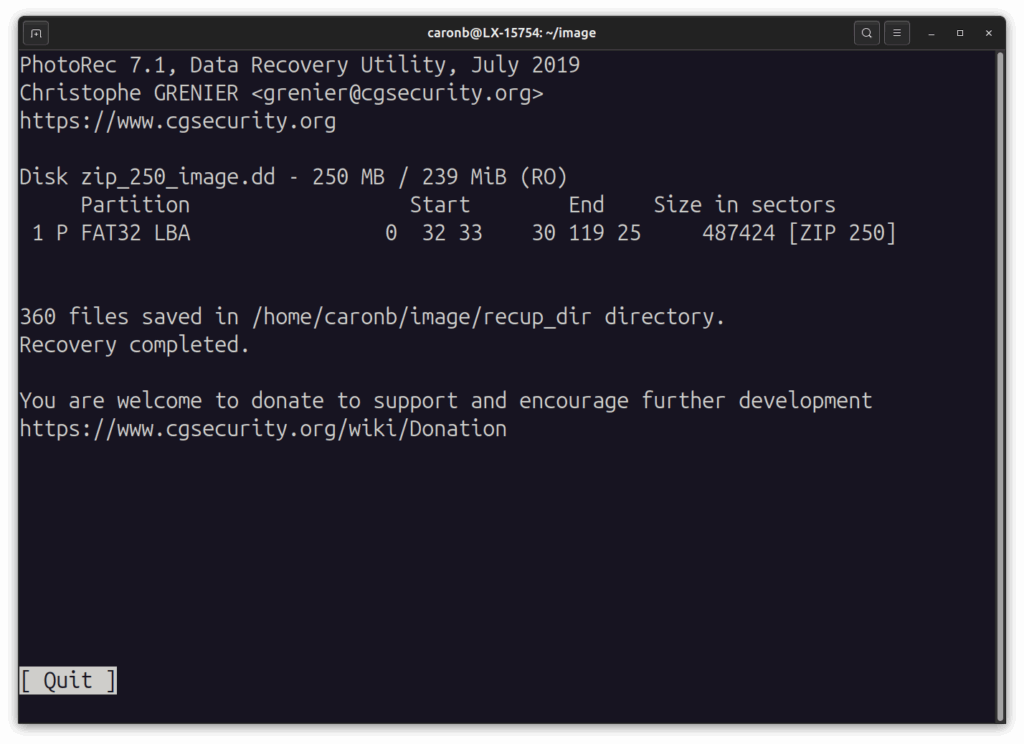
… et le tour est joué : l’outil a créé un dossier recup_directory et y a placé 360 fichiers récupérés.
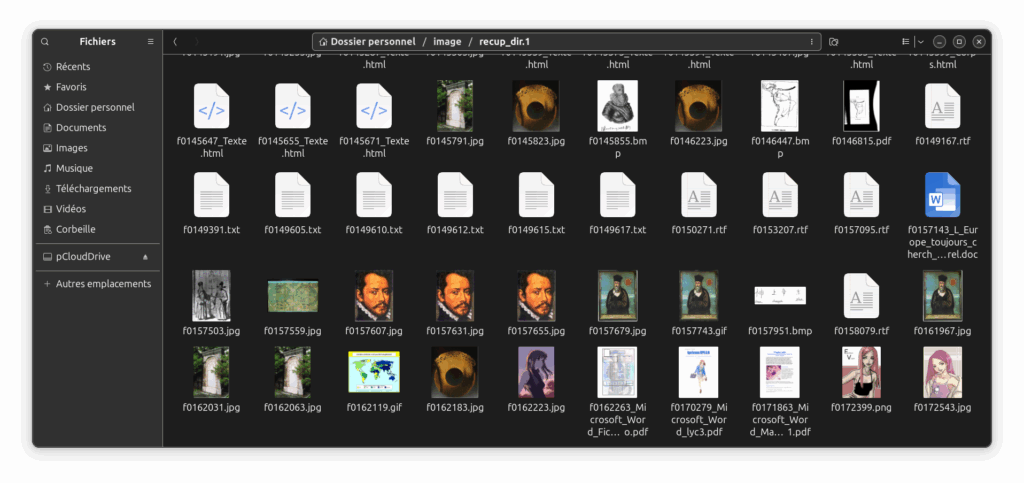
Dans ce dossier, c’est un petit morceau de l’histoire de l’adolescence de ma sœur qui a été récupéré : des scénarios pour un jeu de rôle appelé Lycéenne, son TPE, des scans de cartes de la colonisation espagnole en Amérique du sud…
Les questions éthiques que cela pose
Évidemment, au-delà de la dimension technique, cela pose des questions éthiques et juridiques assez ardues. Restaurer des fichiers que la ou le propriétaire du support avait souhaité voir disparaitre est discutable, mais il est important que nous sachions que c’est possible pour communiquer clairement avec nos donateur·ice·s sur ce que nous ou des lecteur·ice·s futur·e·s serions susceptibles de trouver si nous adoptions cette approche3.
Quelques mots en conclusion
Comme je vous l’ai dit, je ne suis qu’un débutant dans le domaine des digital forensics appliqués aux données patrimoniales, et ce pour une simple raison : les deux institutions dans lesquelles j’ai travaillé (la BnF et la TIB) commencent tout juste à définir leur position sur ce sujet.
Il existe de très nombreux outils à la disposition des archivistes et bibliothécaires pour appliquer ces techniques. J’ai été surpris par leur facilité de mise en œuvre, qui contraste avec la complexité des questions éthiques et juridiques que pose la généralisation de la création des images disques pour la collecte d’archives nativement numériques. Seuls les archivistes et bibliothécaires peuvent y répondre, mais iels ne peuvent le faire qu’en ayant à l’esprit les capacités des processus techniques mentionnés plus haut.
Toujours est-il que Felix a pu produire des images des cinq disquettes ZIP et en extraire le contenu, et que nous avons collectivement fait un pas conséquent dans l’expérimentation du travail avec des images disques !
- Voir à ce propos Kessler (Gary C.) et Carlton (Gregory H.), « A Study of Forensic Imaging in the Absence of Write-Blockers », in Journal of Digital Forensics, Security and Law, 2014, 9(3), accessible sur https://commons.erau.edu/db-security-studies/28 (consulté le 22 septembre 2025). ↩︎
- Pour évaluer l’intérêt de réaliser une image disque, et non une simple copie sécurisée, je vous recommande la lecture du document suivant ; Digital Archival traNsfer, iNgest, and packagiNg Group, « Disk Imaging Decision Factors », DANNNG!, [s.d.], accessible sur https://dannng.github.io/disk-imaging-decision-factors.html (consulté le 23 septembre 2025). ↩︎
- On pourra consulter à ce propos l’article suivant : Lassere (Monique) et Whyte (Jess M.), « Balancing Care and Authenticity in Digital Collections: A Radical Empathy Approach To Working With Disk Images », Journal of Critical Library and Information Studies, vol. 3, no 2 (2021), accessible sur https://doi.org/10.24242/jclis.v3i2.125 (consulté le 23 septembre 2025). ↩︎
Laisser un commentaire