
Récemment nous avons reçu les archives de la grande commande photographique. Cent soixante-dix gigaoctets de données contenant les dossiers envoyés par les candidat·e·s et documentant le processus décisionnel aboutissant à la sélection des deux cents photographes lauréat·e·s et toutes les activités de valorisation du projet. Vingt-trois mille fichiers environ répartis dans près de 3000 répertoires. Et, bien évidemment, des données personnelles à la pelle.
Le désarroi de notre collègue archiviste, confronté à une telle masse était visible. L’idée de parcourir cet ensemble à l’aide de l’explorateur de fichiers et de les ouvrir un par un nous décourageait tous et nous condamnait à l’impuissance et à l’inaction.
Le billet qui suit vise à répondre à un besoin particulier, celui de la recherche dans le contenu de fichiers de formats variés, localisés dans une arborescence. Le traitement de ce fonds d’archives numériques ne se limite pas à cette opération, mais il m’a semblé plus utile de me concentrer sur ce sujet, qui fournit déjà matière à un billet beaucoup trop long.
Je me targue d’être « archiviste numérique », mais j’ignore en réalité une bonne partie du métier, qui consiste notamment à connaître un certain nombre de règles de gestion des documents (durée de conservation, délai d’incommunicabilité, etc.). Je sais en revanche que ces règles dépendent de la nature et du contenu des documents. En matière numérique, on peut parfois s’appuyer sur les noms des répertoires, à condition que le classement ait été bien fait. Mais parfois il est difficile de s’épargner l’examen du contenu propre des fichiers. Y a-t-il un moyen de le faire de manière globale, sans ouvrir chaque fichier et réaliser une recherche dans le corps du texte ?
La réponse est bien sûr oui – vous pouvez tout faire, ou du moins beaucoup, avec des techniques pour le moins éprouvées. Et je commencerai par une technique sous Windows, qui fera saigner mon petit cœur de linuxien convaincu.
L’indexation du contenu des fichiers
Dans Windows, si vous ouvrez votre explorateur de fichiers – oui, le machin qui s’ouvre quand vous cliquez sur n’importe quel répertoire –, vous pouvez faire une recherche sur les données contenues dans le répertoire (ctrl + F et votre curseur se trouvera automatiquement dans la bonne case pour taper un terme de recherche).
Bien pratique pour isoler tous les fichiers de vignettes Thumbs.db et les supprimer d’un coup, par exemple.
Mais cette fonctionnalité va, par défaut, chercher dans le nom du fichier et dans les métadonnées internes (celles du moins que Windows sait trouver). Pour que Windows puisse chercher dans le contenu des fichiers, il faut avoir réalisé une opération préalable qu’on nomme indexation. Par défaut, elle est activée pour les emplacements destinés à abriter du contenu collecté par l’utilisateur·ice, les bibliothèques. Pour simplifier : il s’agit d’emplacements ressemblant à des répertoires standards et accessibles depuis votre menu Windows : Images, Vidéos, Documents, Musique. Lorsque vous y placez des données, le contenu de celles-ci est indexé et vous pouvez chercher dans le texte de vos fichiers.
Vous pouvez également ajouter des emplacements que Windows indexera via les Options d’indexation, afin de vous permettre d’y rechercher du contenu aisément, voire demander l’indexation de tous les emplacements de votre ordinateur – au prix d’un effort conséquent de la machine, qui consomme plus d’énergie au moment de l’indexation.
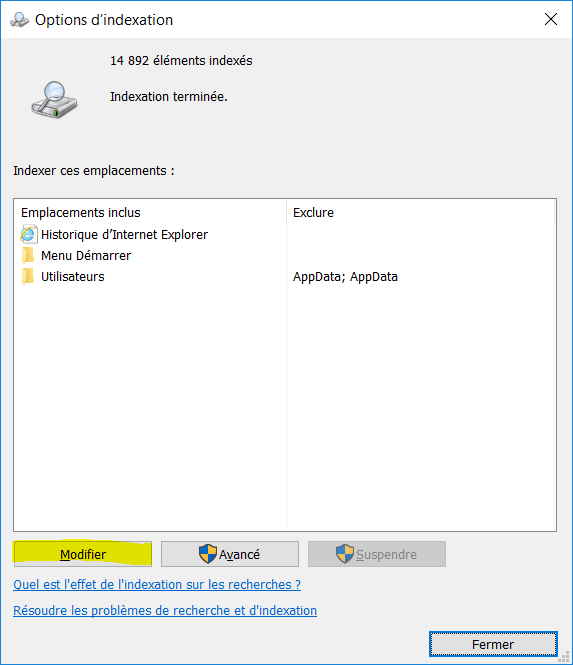
Autre solution : vous pouvez également, avec un clic droit « Inclure dans la bibliothèque » et ajouter ainsi un dossier à une bibliothèque existante, ce qui aura pour effet de l’indexer. Attention, si vous travaillez sur un emplacement réseau, il peut ne pas être indexable, soit pour des raisons techniques, soit parce que votre administrateur ne l’autorise pas.
Cette solution, bien qu’utile, a plusieurs défauts :
- Elle vous renvoie des fichiers, mais il faut encore les ouvrir manuellement pour voir où les mots recherchés se trouvent ;
- Elle ne permet pas, à ma connaissance, de rechercher des motifs (« deux chiffres, puis une barre oblique, puis deux chiffres, puis une barre oblique, puis quatre chiffres » pour trouver une date).
On va devoir passer à des outils en ligne de commande pour faire mieux. Accrochez-vous !
La commande Unix grep
Les systèmes basés sur Unix (MacOS et GNU/Linux) disposent d’une commande merveilleuse pour rechercher dans les fichiers : la commande grep.
Si vous êtes utilisateur·ice Windows, eh bien, euh… arrêtez.

Non, je plaisante bien sûr. Si vous êtes utilisateur·ice Windows, c’est que vous n’avez pas le choix. Dans ce cas, vous disposez de la commande findstr, qui fonctionne de manière assez similaire à grep. Ou bien vous pouvez utiliser grep en installant Cygwin ou Windows Subsystem for Linux. Si vous pratiquez l’une de ces alternatives, n’hésitez pas à me faire part de vos retours, je ne les connais pas très bien.
Allez, un petit exemple de grep sur un ensemble de fichiers :

(Notez que j’ai dû effacer les informations personnelles à la mimine.)
Je vais commenter un peu la ligne de commande :
grep: le nom de la commande – facile ;-r: une option qui cherche récursivement dans les dossiers. Sinon, grep s’arrêterait aux fichiers directement contenus dans le répertoire et omettrait les sous-répertoires ;- Le terme recherché, entre guillemets ;
- L’endroit où on recherche – ici, le point signifie « là où je me trouve », c’est-à-dire à l’emplacement en vert :
/data/ADDN_PrT/.../Appel 2; - La formule
2>/dev/nullpermet d’omettre les erreurs et avertissements. Sinon, vous auriez eu, au milieu de vos résultats, les grommellements de l’outil qui n’arrive pas à ouvrir certains fichiers.
Ici, grep a trouvé une occurrence du mot « Paris » dans un fichier RTF.
Mais là où grep devient vraiment intéressant, c’est qu’il permet de rechercher non seulement des chaînes de caractères précises, mais aussi des motifs comme celui que j’ai donné plus haut. Pour encoder de tels motifs, il faut avoir quelques notions d’expressions régulières, mais ce n’est pas sorcier1. L’intérêt d’apprendre cette technique, c’est qu’elle vous rendra capable de trouver des éléments d’information se conformant toujours à la même syntaxe :
- Numéros de sécurité sociale (chiffre 1 ou 2, trois ensembles de deux chiffres, deux ensembles de trois chiffres, optionnellement une clé sur deux chiffres) ;
- IBAN (« FR76 » puis vingt-trois chiffres séparés par des espaces) ;
- Numéro de téléphone (je ne détaillerai pas ici les différents formalismes, assez variables, mais vous comprenez le principe).
J’en passe, et des meilleures. N’hésitez pas à me signaler tous les motifs intéressants que vous rechercheriez dans des fonds d’archives pour identifier des informations sensibles !
Au passage, certains outils tels qu’ePADD permettent non seulement de réaliser des recherches basées sur des expressions régulières prédéfinies mais proposent aussi des dictionnaires de mots « sensibles » – liés aux maladies, aux substances addictives, au vocabulaire sexuel, etc. Seulement ePADD est fait pour les messageries et ne travaille donc que sur les fichiers MBOX !
Essayons donc grep sur un sous-ensemble de notre fonds :

Les différences avec la ligne de commande précédente :
- L’option
-Pa été ajoutée pour gérer des expressions régulières avancées (on peut écrire-P -rou bien les réunir en écrivant-Prou-rP) ; - Cette fois-ci, la chaîne recherchée n’est pas une série de lettres mais une expression qui signifie « cinq séries de deux chiffres séparées par des espaces » – bien sûr, il existe des manières d’encoder un numéro de téléphone de manière bien plus exacte, mais c’est pour simplifier la logique ici.
Pas de chance, cette fois-ci l’outil de renvoie rien. Pourquoi donc? Parce qu’il ne fonctionne que sur les fichiers textuels (.txt, .csv/tsv, .xml, mais aussi .rtf comme on l’a vu plus haut, etc.). Que faire alors pour les autres ?
pdfgrep
Il existe un utilitaire qui fonctionne comme grep mais est capable de chercher dans les fichiers PDF : pdfgrep. Sa syntaxe est presque la même :
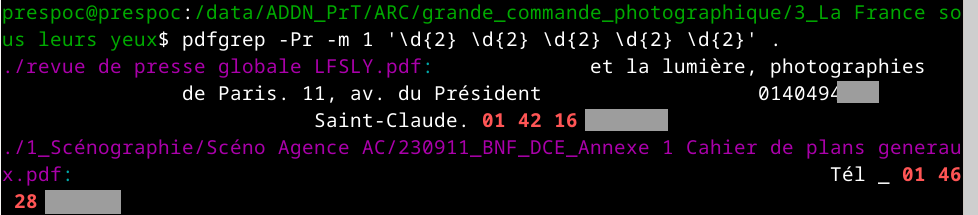
Cette fois-ci, dans le même dossier, on a 38 fichiers qui sont renvoyés et qui contiennent pour la plupart d’entre eux, effectivement, un numéro de téléphone !
La seule chose qui change ici est que je lui ai ajouté une option -m 1 (qui signifie « arrête-toi au premier résultat trouvé et passe au fichier suivant »).
Très bien, ça c’est pour les PDF, mais il y a d’autres fichiers que les PDF n’est-ce pas ? Qu’est-ce qu’on fait pour eux ? Eh bien voici la solution ultime.
Apache Tika
Apache Tika est un « content analysis toolkit » : un ensemble d’outils d’analyse de contenu. Il peut faire une quantité de choses merveilleuses pour un·e spécialiste de la préservation numérique :
- Extraire le texte de fichiers dans un très grand nombre de formats avec l’option
--text; - Faire de l’identification de format de fichier avec l’option
--detect; - Extraire les métadonnées / caractériser de nombreux fichiers avec l’option
--metadata.
Lorsqu’on l’appelle en ligne de commande avec l’option --text, Tika réalise une reconnaissance optique des caractères avec Tesseract. Par conséquent, si vous avez des PDF scannés sans sous-couche texte, il est également capable d’en extraire le texte. En revanche, cela demande un temps nettement plus conséquent, donc selon les cas vous aurez peut-être intérêt à désactiver ce comportement.
Pour info, c’est l’outil utilisé par les équipes qui ont travaillé sur les Panama Papers ! Voir à ce propos « The People and Tech Behind the Panama Papers », Mar Cabra et Erin Kissane, 11 avril 2016, disponible sur https://source.opennews.org/articles/people-and-tech-behind-panama-papers/.
Cette fois-ci, au lieu de faire une recherche directe, on va utiliser Tika en mode batch pour préparer le terrain, de la manière suivante :
tika --text -i dossier_source/ -o dossier_cible/
L’option -i (pour input) introduit le dossier qu’on souhaite traiter ; l’option -o (pour output) le dossier où l’on souhaite placer le résultat. Tika produira un fichier textuel pour chaque fichier contenu dans le dossier analysé, nommé selon le nom du fichier d’origine suffixé par l’extension « .txt ». Dans ce fichier textuel, on trouvera le texte extrait par Tika, et on pourra ensuite faire une recherche avec grep sur l’ensemble.
Reprenons notre outil grep, en travaillant cette fois-ci sur l’arborescence produite par Tika contenant exclusivement du texte brut. Désormais, la ligne de commande
grep -Pr '\d{2} \d{2} \d{2} \d{2} \d{2}' . 2>/dev/null
renvoie 46 résultats, parmi lesquels on trouve les suivants :
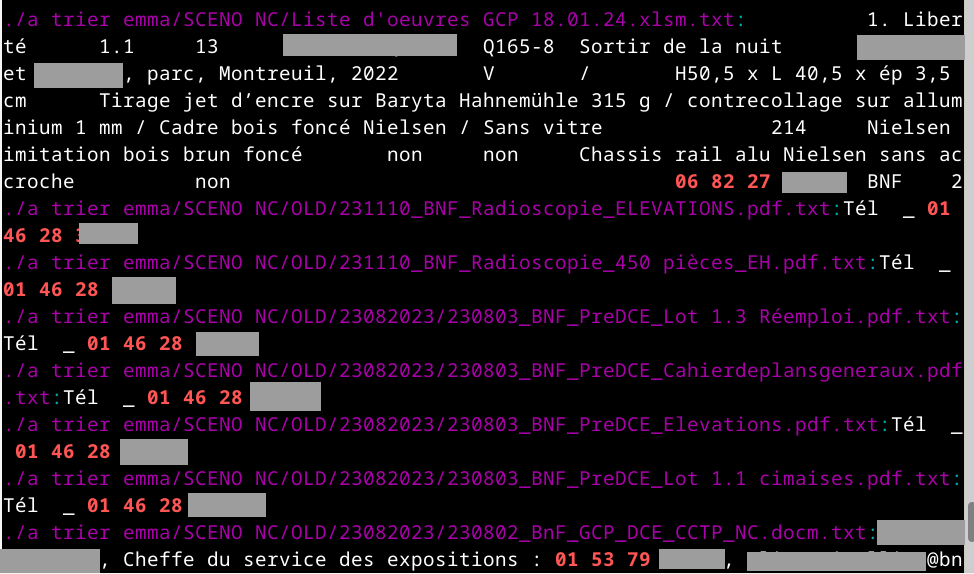
Ici, on voit bien aux noms des fichiers (en violet) que Tika a pu extraire du texte de fichiers DOCM et XLSM2.
Je m’arrêterai là pour aujourd’hui. Archivistes, ces méthodes vous semblent-elles utiles ? Peut-être en utilisez-vous d’autres ? N’hésitez pas à me les proposer en commentaire !
1De nombreux tutoriels existent en ligne, comme celui de Zeste de savoir : https://zestedesavoir.com/tutoriels/pdf/3651/les-expressions-regulieres-1.pdf.
2Pour être tout à fait complet, il faut préciser que l’extraction de texte de Tika, dans le cas des PDF, ne prend que les éléments textuels destinés à être affichés au lecteur, et non les métadonnées. En l’occurrence, pour réaliser une identification complète des données personnelles, il faudrait aussi faire une recherche sur les métadonnées des PDF, ceux-ci intégrant, tout comme les photographies, les numéros de téléphone portable de leurs producteurs !
Laisser un commentaire