
Cela fait plusieurs mois que je n’ai pas écrit dans ce blog, et ça me navre. Mon activité professionnelle ne me laisse pas assez d’énergie pour me lancer dans une telle entreprise après une journée de travail. Depuis avril dernier, je ne publie donc plus que pendant mes vacances. Or je suis en vacances, et rien ne semble venir. Je vais donc me forcer un peu et vous faire part de quelques dernières expérimentations, dans le prolongement de mon précédent billet.
Il se trouve en effet que j’avais un ordinateur familial acheté au début des années 2000 qui achevait son séjour au purgatoire dans la maison de mes parents, avant de s’envoler vers les tristes cieux des DEEE.
Dans ce billet, je vais donc faire un pas de plus et vous raconter comment j’ai fait une image de ce disque, puis je passerai en revue les méthodes et outils permettant
- D’identifier bon nombre de fichiers système automatiquement ;
- De récupérer beaucoup d’informations importantes sur les fichier supprimés – et pas que les fichiers supprimés eux-mêmes, comme on avait vu dans le précédent billet ;
- De restaurer individuellement un de ces fichiers.
Prêt·e·s ? C’est parti !
Extraction du disque dur
J’ai décidé de tenter d’extraire le disque dur et de lui faire subir un traitement similaire à celui de la disquette ZIP. L’opération s’est révélée plus facile que prévu : déconnecter la nappe PATA et son alimentation, dévisser quatre vis et dégager le bidule.

Connexion du disque dur
Connecter ce disque dur à mon ordinateur récent n’est pas très compliqué. Bien entendu, un bloqueur d’écriture tel que le Tableau TK35u aurait été idéal, mais je n’ai pas encore décidé d’investir de l’argent dans un matériel d’acquisition professionnel. J’ai donc opté pour un bête câble de connexion IDE/PATA vers USB tel que celui-ci. Sans doute pas le plus robuste, mais ça me suffisait pour un petit test.

Notez que, comme il est nécessaire d’alimenter le disque dur en électricité, le boîtier doit être branché sur le secteur.
Comme Thomas Ledoux, mon cher ex-collègue de la BnF, me l’a plus tard indiqué, il peut être utile de réaliser une copie du disque dur sans l’extraire, si cette manipulation semble complexe ou risquée. La méthode qu’il recommande est de booter l’ordinateur avec SystemRescue sur une clé USB, ce qui permet de lancer une copie du disque dur sur un disque dur externe. Si la machine n’a qu’un port USB, le système est si léger qu’il peut généralement être chargé intégralement sur la mémoire RAM, et la clé USB peut alors être déconnectée. Je n’ai pas testé cette solution mais la garde sous le coude pour une prochaine fois.
Création de l’image disque
Comme pour l’image disque, j’ai utilisé dc3dd après avoir tenté une originale solution du même Thomas Ledoux, qui crée l’image et la compresse en une seule ligne de commande :
dd if=/dev/sda | gzip -v6 | of=~/monImage.gzLes images disques se prêtent d’autant mieux à la compression que le support d’origine a été peu utilisé. Pour un gain d’espace maximum, il vaudrait mieux réaliser l’image puis la compresser, mais vous n’avez pas forcément l’espace nécessaire pour stocker une image d’un volume de plus d’un téraoctet, d’où l’intérêt de compresser à la volée.
Malheureusement, cette excellente solution n’a pas fonctionné sur le disque dur en question. Je me suis donc rabattu sur la solution dc3dd. Après une première tentative infructueuse, sans doute due à une défaillance de la connectique, j’ai obtenu un fichier .dd de 80 Go et un fichier de log.
Recherche de fichiers système avec FileTrove
L’identification du format des fichiers est une opération absolument fondamentale dans les processus de préservation numérique, mais quand on acquiert un disque dur de travail complet, on risque fort de se retrouver avec de très nombreux fichiers système qui n’ont pas particulièrement d’intérêt pour l’archiviste, à moins de vouloir faire une analyse forensique très poussée. On peut généralement les identifier par leur nom plutôt que par une signature numérique interne. Mais un outil intéressant pour compléter cette identification par nom de fichier est FileTrove. Ce logiciel embarque Siegfried, qui identifie le format des fichiers selon le registre PRONOM ; en outre, il calcule une somme de contrôle selon plusieurs algorithmes. Mais la principale plus-value de l’outil, c’est qu’il compare cette somme de contrôle à celles enregistrées dans la base National Software Reference Library (NSRL) qui recense les empreintes numériques de fichiers système et d’application. L’usage le plus courant est le même que la criminalistique numérique : évacuer ces fichiers qui ne sont pas utiles à l’enquêteur / l’archiviste.
In most cases, NSRL file data is used to eliminate known files, such as operating system and application files, during criminal forensic investigations. This reduces the number of files which must be manually examined and thus increases the efficiency of the investigation.
FileTrove travaille sur un dossier et ses sous-dossiers récursivement, il est donc nécessaire de monter l’image disque obtenue (voir le précédent billet pour savoir comment faire ça). Une fois le rapport de FileTrove produit, il est facile de filtrer les fichiers afin de ne considérer que les fichiers spécifiques à l’utilisateur·ice.
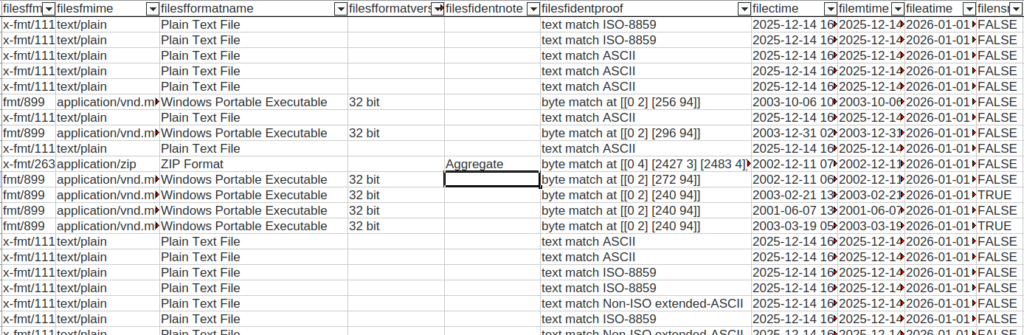
L’avantage de l’outil c’est aussi qu’il est extrêmement rapide : pour faire tout cela sur environ 50 000 fichiers, il ne lui aura fallu qu’un quart d’heure sur mon portable (i7, 32 Go de RAM).
Un grand merci à Alex Holz pour sa recommandation de FileTrove, qu’il a présenté à la bake-off session d’iPRES 2024 !
Recherche de fichiers supprimés avec fiwalk
Vous vous souvenez peut-être que j’avais récupéré des fichiers supprimés sur ma disquette ZIP avec photorec dans mon précédent billet. Une autre possibilité pour le faire de manière plus sélective est de partir de la sortie de l’outil fiwalk, qui liste les fichiers qu’il trouve sur un disque ou une image de disque, qu’ils soient alloués (référencés par le système de fichiers) ou non (supprimés). Il peut aussi calculer une empreinte numérique et faire de l’identification de format en lançant Unix File sur les fichiers. On obtient en sortie un (très gros) fichier XML au format dfxml (pour Digital Forensics XML). Vu sa taille (194 Mo), j’ai préféré le charger dans le logiciel de base de données XML BaseX afin de l’interroger en XPATH/XQuery. Par exemple, pour trouver les fichiers supprimés dont l’identification du format révèle un fichier de contenu :
declare namespace dfxml="http://www.forensicswiki.org/wiki/Category:Digital_Forensics_XML";
//dfxml:fileobject[dfxml:unalloc and dfxml:libmagic!="empty" and dfxml:libmagic!="data " and dfxml:filesize!="0"]Le retour de fiwalk pour un fichier supprimé ressemble à ceci :
<fileobject>
<parent_object>
<inode>23382048</inode>
</parent_object>
<filename>Documents and Settings/Philippe/Local Settings/Temporary Internet Files/Content.IE5/S1SJW3WN/culture_journal_9h[1].jpg</filename>
<partition>1</partition>
<id>12065</id>
<name_type>r</name_type>
<filesize>15809</filesize>
<unalloc>1</unalloc>
<used>1</used>
<inode>213569923</inode>
<meta_type>1</meta_type>
<mode>511</mode>
<nlink>0</nlink>
<uid>0</uid>
<gid>0</gid>
<mtime prec="2">2011-03-04T13:26:06</mtime>
<atime prec="86400">2011-03-03T23:00:00</atime>
<crtime prec="2">2011-03-04T13:26:04</crtime>
<libmagic>JPEG image data, JFIF standard 1.01, aspect ratio, density 1x1, segment length 16, comment: "CREATOR: gd-jpeg v1.0 (using IJG JPEG v62), quality = 90", baseline, precision 8, 413x500, components 3 </libmagic>
<byte_runs>
<byte_run file_offset="0" fs_offset="395702272" img_offset="395734528" len="15809"/>
</byte_runs>
</fileobject>Ce qui me frappe ici, par rapport à la récupération en masse réalisée par photorec, c’est qu’il est capable de retrouver le chemin absolu du fichier sur la partition, alors que photorec attribuait des noms aléatoires à la plupart des fichiers qu’il récupérait.
Pour plus d’information sur fiwalk, je vous invite à consulter Using Fiwalk to Generate Filesystem Metadata, un support de formation proposé par la University of North Carolina.
Restauration individuelle avec dd
Dans l’extrait précédent, l’information importante pour extraire l’un de ces fichiers supprimés est l’élément <byte_runs> : on y trouvera un ou plusieurs éléments <byte_run> qui indiquent où se situent les données. Lorsque les données sont fragmentées, donc stockées à plusieurs emplacements discontinus, il est nécessaire de mettre bout à bout plusieurs séquences d’octets représentés par ces éléments <byte_run>. Ici, il n’y a qu’un élément, ce qui nous facilite la tâche. Il suffit de copier la partie de l’image disque qui commence à l’offset indiqué dans l’attribut byte_run/@img_offset (679374336) et se termine X octets plus loin, X étant la valeur de l’attribut byte_run/@len (pour « length »).
Ça tombe bien : la commande dd est exactement capable de faire ça :
dd if=monImage.dd of=monFichier.jpg count=15809 skip=395734528 iflag=skip_bytes,count_bytesIci, le paramètre skip indique l’offset de l’image disque où la copie doit commencer (valeur de l’attribut byte_run/@img_offset) et le paramètre count le nombre d’octets que la commande doit copier (valeur de l’attribut byte_run/@len). Rappel pour celleux qui se sont endormis pendant la lecture du précédent billet : le paramètre « if » (pour input file) indique le chemin vers l’image disque et le paramètre « of » (pour output file) le fichier à créer, La séquence d’octets ainsi extraite sera enregistrée dans le fichier monFichier.jpg.
En guise de conclusion, une petite histoire
Quelques jours après le début de mes expériences, je tombe sur ce pouet sur Mastodon, qui recherchait un épisode bonus de Naheulbeuk. Comme tout adepte du jeu de rôle et d’heroic fantasy qui se respecte, j’avais moi aussi téléchargé l’intégralité de la production de cette aventure parodique, avant de tout supprimer au gré d’un tri drastique de mes données personnelles.
J’ai tenté de retrouver parmi les fichiers supprimés cette petite pochade. Parmi les 26 Go exhumés par photorec, il fallait cibler les fichiers MP3 – mais cela renvoyait toujours plus de 700 fichiers dont les noms n’étaient plus signifiant, car regénérés par l’outil :
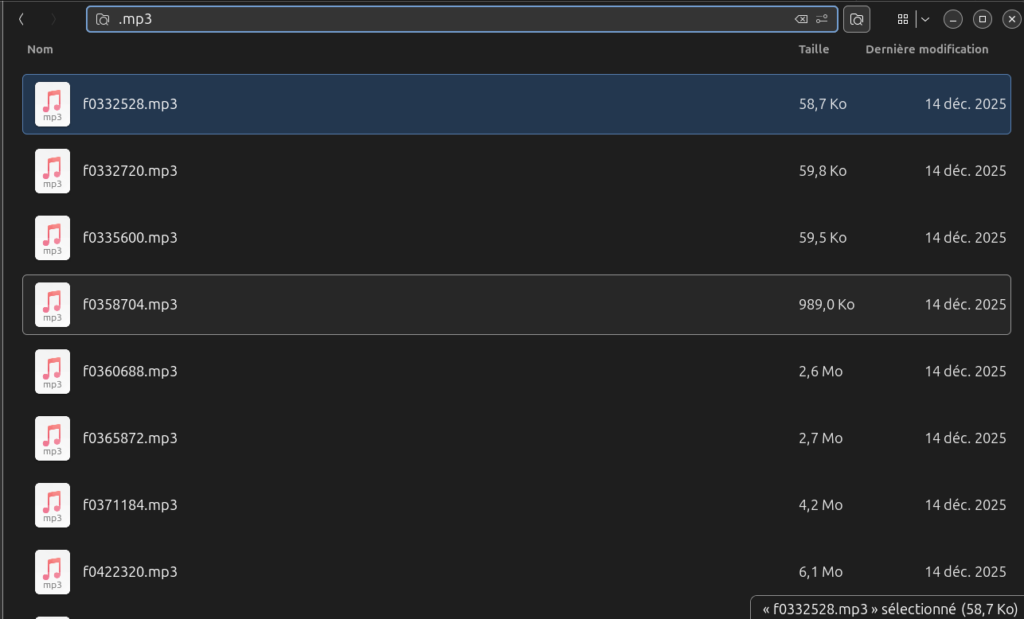
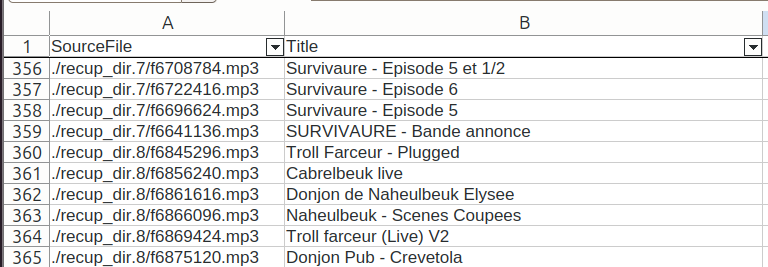
La solution que j’ai trouvée est de me baser sur les métadonnées internes des fichiers MP3. La commande suivante extrait le titre (-Title) de tous les fichiers ayant l’extension .mp3 dans l’arborescence des fichiers récupérés (-r signifie « récursif ») et l’enregistre dans un fichier CSV (-csv) :
$ exiftool -ext mp3 -csv -r -Title . > ~/track_titles.csv
41 directories scanned
694 image files readLe résultat :
Comme je l’indiquais plus haut, une recherche dans le retour de fiwalk m’aurait aussi permis de le retrouver, car l’outil est parfois capable de restituer le chemin absolu et le nom du fichier supprimé :
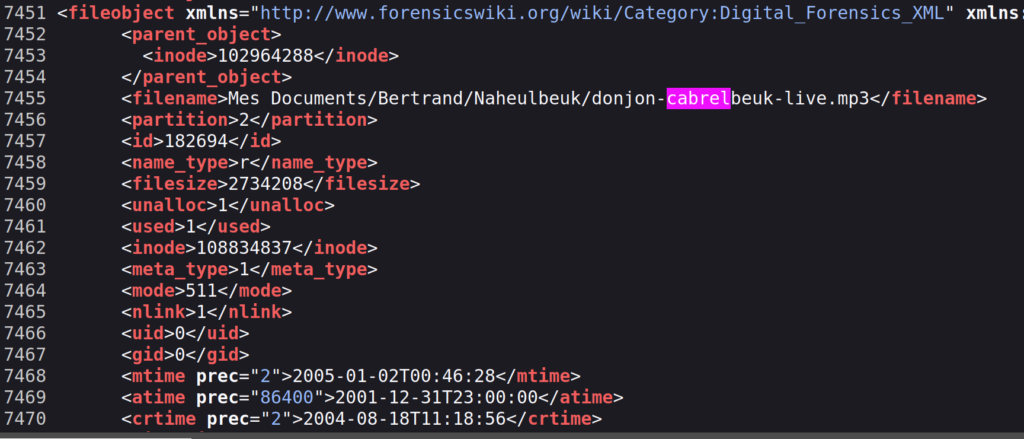
Voilà un petit exercice pratique qui tombait à pic pour pratiquer l’exploration dans des fichiers supprimés !
Tout cela donne un certain nombre d’outils pour aborder un vieux disque dur, mais comment identifier des fichiers de contenu dans 50 000 fichiers et une arborescence labyrinthique ? Peut-être verrons-nous ça dans un prochain billet. Et, pour ajouter un petit cliffhanger trollesque, peut-être même qu’il y aura un peu d’IA dedans, parce qu’il faut bien avouer que ces satanées technologies sont terriblement efficaces pour trouver une aiguille dans une botte de foin…
Laisser un commentaire